本文作者
Santiago Flores Kanter 亚马逊云科技高级解决方案架构师
Ravi Yadav 亚马逊云科技首席容器专家
校译作者
梁宇 亚马逊云科技专业服务团队 DevOps 顾问
在 Amazon ECS 服务上运行分布式机器学习工作负载可让 ML 团队更加专注于创建、训练和部署模型,而不是花时间去管理容器编排引擎。凭借着简单的架构、控制节点的无感升级以及集成了原生的 Amazon IAM 认证服务,Amazon ECS 为运行 ML 项目提供了一个绝佳的环境。此外,Amazon ECS 还支持使用英伟达的 GPU 以及提供预装英伟达内核驱动程序和 Docker 运行时的优化镜像。
通常在使用分布式方法进行模型训练的时候,有两种资源部署方式可供选择。一种是使用包含多个 GPU 的单节点实例,另一种则是多节点实例,每一个实例包含一个或多个 GPU 。除资源以外,相对应的还有几种技术支持实现分布式模型训练。它们分别是流水线并行(模型的不同层分别被加载到不同的 GPU 中)、张量并行(将单层分割到不同的 GPU 中)以及分布式数据并行(每一个 GPU 中都会加载模型的完整副本,训练数据会被分割以及并行处理)。
本文旨在展示利用 PyTorch 和 RayTrain 这两个库在 Amazon ECS 运行的容器中实现分布式数据并行的机器学习模型训练。通过深入研究本文的实现,读者可以获得一个可用的示例并由此开启分布式机器学习的旅程。与此同时,读者也可将本文的实现作为基础样例,并根据具体情况的模型、数据以及用例进行定制化。
解决方案概述
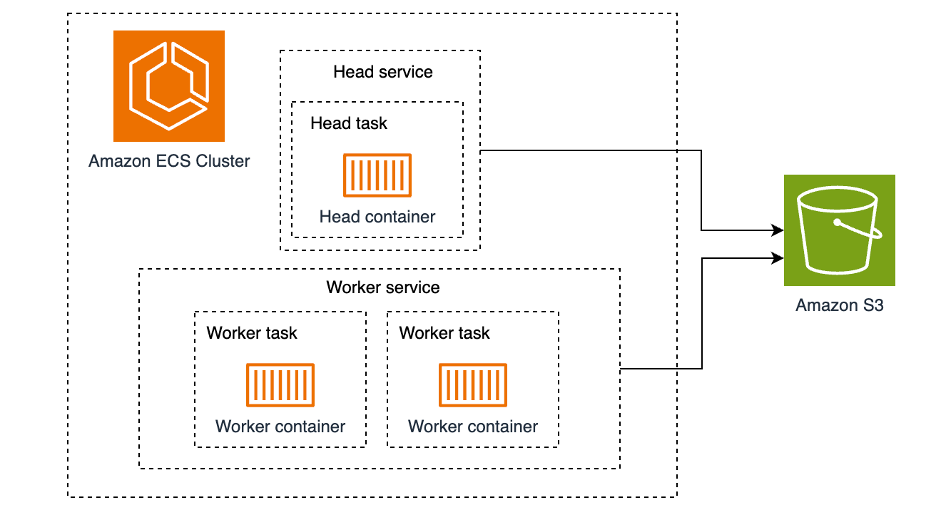
本解决方案由一个 ECS 集群组成,该集群上运行的是 Ray 集群。Ray 集群是由一组 worker 进程以及一个 Ray head 进程组成,所有的 worker 进程都连接到这个 head 进程。因此,我们将会在 ECS 集群中部署两种服务:Ray head 以及 Ray worker。我们将使用单个 ECS task 来运行 Ray head 服务,而对于 Ray worker 服务,为了展示多节点的场景,我们将使用两个 ECS task 来运行。这里所有的 task 都只包含一个 container。Amazon S3 将用作这些 task 之间的共享存储。
先决条件
读者在演练前需作如下准备:
一个亚马逊云科技帐号
Terraform 命令行工具
安装了 session manager 插件的 Amazon CLI
亚马逊云科技帐号里的 G 类型实例的按需配额需要大于等于 8(本次方案将使用两个大小为 g5.xlarge 的节点)
Amazon ECS
Amazon S3
PyTorch
Ray Train
演练
本次演练中,我们将创建一个 S3 桶作为共享存储。然后,我们在 ECS 集群中创建两个自动扩缩容的组(ASG),其中一个组配置大小为 m5.large 的实例,用于部署 Ray head服务;另一个组配置大小为 g5.xlarge 的实例(每一个实例都有 A10 GPU),用于部署 Ray worker 服务。基础架构准备完成之后,我们将使用 FashionMNIST 数据集对 resnet18 模型进行分布式训练。由于该模型可以在单个 GPU 中完整加载,因此我们将采取分布式数据并行的方法来训练。
部署基础设施
在继续进行演练之前,请先考虑以下几点:
遵循在私有子网运行此类工作负载的最佳实践。由于下载数据集需要连接互联网,因此我们创建了一个 NAT 网关和一个 Internet 网关。
使用了单个子网来改善延迟,从而令所有实例都在同一可用区(AZ)中启动。同时,这也避免了可用区之间数据传输的花费。
工作节点使用了一种集群置放策略。这种策略可使其中运行的工作负载享有低延迟的网络性能。
Amazon ECS 不支持 Ray autoscaling。但是,可以通过配置 Amazon ECS 的服务自动扩展来对 ECS task 数进行增加或减少,从而实现相同的效果。
在分布式训练模型训练中,对每个工作节点配备更多的 GPU 意味着更好的性能。例如,您的模型训练任务需要 8 个 GPU,那么通常来说,使用 1 个带有 8 个 GPU 的实例进行训练,在性能方面要比使用 8 个各自带有 1 个 GPU 的实例集要好。对于容器来说也是如此,1 个容器享有 8 个 GPU 的性能比 8 个容器各自享有 1 个 GPU 的性能要好。这是由于运行训练任务的集群中每个节点都需要额外的开销。为了降低实验成本,本次演练使用 g5.xlarge(每个实例只有一个 GPU)。
步骤
1. 克隆 ecs-blueprints 代码库
git clone https://github.com/aws-ia/ecs-blueprints.git2. 部署基础设施
cd ./ecs-blueprints/terraform/ec2-examples/core-infra
terraform init
terraform apply -target=module.vpc \ -target=aws_service_discovery_private_dns_namespace.this3. 部署 distributed ML training blueprint
cd ../distributed-ml-training
terraform init
terraform apply代码执行完成之后在输出中查找并记录下 S3 桶的名字,下一部分内容会用到。
运行训练任务
基础设施创建完成后,我们就可以运行分布式训练的脚本了。为了简单起见,我们连接到一个容器中并在里面直接运行该脚本。当然,使用 Amazon SageMaker 的 Notebooks 或者 Amazon Cloud9 会获得更好的用户体验。
1. 连接到运行 Ray head 服务的 EC2 节点。
HEAD_INSTANCE_ID=$(aws ec2 describe-instances \ --filters 'Name=tag:Name,Values=ecs-demo-distributed-ml-training-head' 'Name=instance-state-name,Values=running' \ --query 'Reservations[*].Instances[0].InstanceId' --output text --region us-west-2 ) aws ssm start-session --target $HEAD_INSTANCE_ID --region us-west-22. 在该 EC2 节点查找容器 ID 并启动一个交互式 Shell。这可让我们在容器里面执行相关的命令(如果容器的状态不正常的话,以下命令有可能会报错,多尝试几次即可)。
CONTAINER_ID=$(sudo docker ps -qf "name=.*-rayhead-.*") sudo docker exec -it $CONTAINER_ID bash3. 检查 Ray 集群的状态。
ray status输出示例:
(...)
Node status
---------------------------------------------------------------
Healthy:
1 node_a3d74b6d5089c52f9848c1529349ba5c4966edaa633374b0566c7d69
1 node_a5a1aa596068c73e17e029ca221bfad7a7b0085a0273da3c7ad86096
1 node_3ae0c0cabb682158fef418bbabdf2ea63820e8b68e4ae2f4b24c8e66
Pending:
(no pending nodes)
Recent failures:
(no failures)
(...)
Resources
---------------------------------------------------------------
Usage:
0.0/6.0 CPU
0.0/2.0 GPU
0B/38.00GiB memory
0B/11.87GiB object_store_memory
Demands:
(no resource demands)如果您没有看到 2.0 GPU,那么有可能是 Ray worker 服务还没有启动完毕。只需要稍等几分钟让 Ray worker 服务启动并自动加入到集群即可。
4. 将前面记录的 S3 桶的名字作为参数传递给分布式训练脚本并执行该脚本。
export RAY_DEDUP_LOGS=0 # Makes the logs verbose per each process in the training
cd /tmp
wget https://raw.githubusercontent.com/aws-ia/ecs-blueprints/main/terraform/ec2-examples/distributed-ml-training/training_example.py
python training_example.py REPLACE_WITH_YOUR_BUCKET_NAME输出示例:
(...)
Wrapping provided model in DistributedDataParallel.
(...)
(RayTrainWorker pid=227, ip=10.0.2.255) [Epoch 0 | GPU0: Process rank 0 | Batchsize: 128 | Steps: 235 | Total epoch time: 17.660568237304688]
(RayTrainWorker pid=234, ip=10.0.15.42) [Epoch 0 | GPU0: Process rank 1 | Batchsize: 128 | Steps: 235 | Total epoch time: 17.65453052520752]
(RayTrainWorker pid=227, ip=10.0.2.255) [Epoch 1 | GPU0: Process rank 0 | Batchsize: 128 | Steps: 235 | Total epoch time: 17.172431230545044]
(RayTrainWorker pid=234, ip=10.0.15.42) [Epoch 1 | GPU0: Process rank 1 | Batchsize: 128 | Steps: 235 | Total epoch time: 17.17476797103882]
(RayTrainWorker pid=227, ip=10.0.2.255) [Epoch 2 | GPU0: Process rank 0 | Batchsize: 128 | Steps: 235 | Total epoch time: 16.807305574417114]
(RayTrainWorker pid=234, ip=10.0.15.42) [Epoch 2 | GPU0: Process rank 1 | Batchsize: 128 | Steps: 235 | Total epoch time: 16.807661056518555]
(RayTrainWorker pid=227, ip=10.0.2.255) [Epoch 3 | GPU0: Process rank 0 | Batchsize: 128 | Steps: 235 | Total epoch time: 17.16184115409851]
(RayTrainWorker pid=234, ip=10.0.15.42) [Epoch 3 | GPU0: Process rank 1 | Batchsize: 128 | Steps: 235 | Total epoch time: 17.164414882659912]
(RayTrainWorker pid=227, ip=10.0.2.255) [Epoch 4 | GPU0: Process rank 0 | Batchsize: 128 | Steps: 235 | Total epoch time: 17.43423628807068]
(RayTrainWorker pid=234, ip=10.0.15.42) [Epoch 4 | GPU0: Process rank 1 | Batchsize: 128 | Steps: 235 | Total epoch time: 17.430140495300293]
(RayTrainWorker pid=234, ip=10.0.15.42) [Epoch 5 | GPU0: Process rank 1 | Batchsize: 128 | Steps: 235 | Total epoch time: 17.319995880126953]
(RayTrainWorker pid=227, ip=10.0.2.255) [Epoch 5 | GPU0: Process rank 0 | Batchsize: 128 | Steps: 235 | Total epoch time: 17.331279277801514]
(RayTrainWorker pid=234, ip=10.0.15.42) [Epoch 6 | GPU0: Process rank 1 | Batchsize: 128 | Steps: 235 | Total epoch time: 17.402108669281006]
(RayTrainWorker pid=227, ip=10.0.2.255) [Epoch 6 | GPU0: Process rank 0 | Batchsize: 128 | Steps: 235 | Total epoch time: 17.385886192321777]
(RayTrainWorker pid=234, ip=10.0.15.42) [Epoch 7 | GPU0: Process rank 1 | Batchsize: 128 | Steps: 235 | Total epoch time: 16.865890741348267]
(RayTrainWorker pid=227, ip=10.0.2.255) [Epoch 7 | GPU0: Process rank 0 | Batchsize: 128 | Steps: 235 | Total epoch time: 16.86034846305847]
(RayTrainWorker pid=234, ip=10.0.15.42) [Epoch 8 | GPU0: Process rank 1 | Batchsize: 128 | Steps: 235 | Total epoch time: 17.0880389213562]
(RayTrainWorker pid=227, ip=10.0.2.255) [Epoch 8 | GPU0: Process rank 0 | Batchsize: 128 | Steps: 235 | Total epoch time: 17.094018697738647]
(RayTrainWorker pid=234, ip=10.0.15.42) [Epoch 9 | GPU0: Process rank 1 | Batchsize: 128 | Steps: 235 | Total epoch time: 17.191094160079956]
(RayTrainWorker pid=227, ip=10.0.2.255) [Epoch 9 | GPU0: Process rank 0 | Batchsize: 128 | Steps: 235 | Total epoch time: 17.189364910125732]
(..)
╭───────────────────────────────╮
│ Training result │
├───────────────────────────────┤
│ checkpoint_dir_name │
│ time_this_iter_s 182.976 │
│ time_total_s 182.976 │
│ training_iteration 1 │
│ accuracy 0.8852 │
│ loss 0.41928 │
╰───────────────────────────────╯
(...) Total running time: 3min 7s
Result(
metrics={'loss': 0.4192830347106792, 'accuracy': 0.8852},
(...)
)上述日志展示了:
GPU ID 表示的是 GPU 序号。这里只有 GPU 0 是因为每一个实例只配备了一个 GPU。
Process rank 是全局唯一的,这里只有 0 或者 1 是因为我们一共只有两个 GPU。
Epoch number 是从 0 到 9。
Batch size 是指每次迭代所使用的训练数据示例的数量。
Steps 指的是多整个数据集完成一次遍历所需要的循环次数。在本例子中是 235。但是这个数字从何而来?FashionMNIST 数据集有 60,000 个示例。如果 batch size 是 128 的话,我们需要在每个 epoch 执行 469 个 steps 才能遍历整个数据集(60,000/128)。然而,我们总共只有 2 个 GPU,那么 469 个 steps 要平均分配到每个 GPU 上,即 469/2,所以得到我们在日志里面看到的 235 个 steps 。
清理资源
为了避免产生额外费用,请记住清理之前使用 Terraform 创建的所有资源。
1. 删除 distributed ML training blueprint
terraform destroy2. 删除基础设施
cd ../core-infra
terraform destroy总结
在本文中,我们使用了 Amazon ECS 来运行分布式数据并行的模型训练。我们从基础设施的构建开始,包括 ECS 集群,容量提供程序,任务定义和服务部署。然后,我们使用了 FashionMNIST 数据集对 resnet18 模型进行训练,同时通过 Ray Train 和 PyTorch 库将训练的工作负载分布在多个 GPU 中。与使用单个 GPU 相比,使用分布式方法能让我们更快地完成模型训练。
在开启您的分布式训练之旅前,请务必查看 Amazon ECS GPU 的文档,了解更多 Amazon ECS 支持的不同配置和其他功能的相关信息:
https://docs.aws.amazon.com/AmazonECS/latest/developerguide/ecs-gpu.html
原文链接:
https://aws.amazon.com/blogs/containers/distributed-machine-learning-with-amazon-ecs/
点击阅读原文查看博客,获得更详细内容!
本篇作者

Santiago Flores Kanter
亚马逊云科技高级解决方案架构师,专门从事容器、机器学习和无服务器领域,为数字原生客户提供支持和设计云解决方案。

Ravi Yadav
亚马逊云科技首席容器专家,Ravi 领导亚马逊云科技容器服务的上市策略,为 ISV 和数字原生客户提供支持。

梁宇
亚马逊云科技专业服务团队 DevOps 顾问,主要负责 DevOps 技术实施。尤为热衷云原生服务及其相关技术。在工作之余,他喜欢运动,以及和家人一起旅游。

星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」

听说,点完下面4个按钮
就不会碰到bug了!